 Channing Chen's Blog
Channing Chen's Blog
An introduction of ASVspoof (unfinished)
ASVspoof(Automatic Speaker Verification and Spoofing Countermeasures Challange)是针对音频伪造攻击特设立的比赛,主办方是ISCA(International Speech Communication Association),该大会是推动音频伪造、防伪造攻击的一大主力,现已经举办了4届(2015-2021 每两年一届)。本文结合以下两篇总结性论文对该比赛的情况进行简要介绍,主要包括比赛任务、数据集、结果,以及比赛中涌现出来的主要工作等。ASVspoof2015和ASVspoof2017较早并且主要面向传统的ASV系统攻防挑战而不是目前主流的神经网络结构,因此以下重点关注ASVspoof2019、ASVspoof2021。
[1] ASVspoof 2021: accelerating progress in spoofed and deepfake speech detection
[2] ASVspoof 2019: A large-scale public database of synthesized, converted aznd replayed speech
[3]ASVspoof 2019: Spoofing Countermeasures for the Detection of Synthesized, Converted and Replayed Speech
Challenge
ASVspoof至今已经举办四届,每一届围绕面向 ASV(Adversarial speaker recognition)系统的音频伪造攻防聚焦不同的重点展开。ASVspoof2015主要面向LA(Logical Access)域攻击展开攻防,主要面向基于语音合成和语音转换的音频伪造攻击。ASVspoof2017加入了PA(Physical Access)域攻击,主要围绕音频重放攻击。伴随着基于神经网络架构的ASV的兴起,ASVspoof2019在ASVspoof2015的基础上主要面向主流的基于ASV神经网络模型展开了攻防挑战,并且构建了专用的数据集和评价指标t-DCF。ASVspoof2021加入了DF(Audio Deepfake)赛道的攻防挑战,并且在原有基础上进一步丰富了数据集,并提供了四个官方Baseline。
-
Logical Access(LA):LA表示直接访问ASV API进行攻击的场景,例如电话银行等。攻击者直接将合成的音频通过数字空间输入给目标系统,无需经过物理播放-再录音的过程,从而避免了传播过程中的由设备和空间信道造成的干扰。在
ASVspoof2021种LA赛道引入了codec。 -
Physical Access(PA):PA表示攻击者需要将音频通过扬声器向环境中固定的麦克风进行播放,环境中存在各种各样的障碍物,如地板、墙、桌椅等,因此被录制的音频种同时也引入了额外的干扰。
-
Deepfake(DF):DF和之前的spoof的主要区别在于,攻击者欺骗的对象是人,而不是ASV系统。其目标人群可能是名人、政治人物(如前段时间的泽连斯基事件)等,攻击者能够利用目标对象的少量预料,提取预料中的声纹信息,通过相关技术伪造DF样本,再通过互联网社交媒体等手段达到传播虚假信息、谣言、诈骗等恶意目的。因此DF攻击样本理论上应该更加注重听感上的音色变换。
Dataset
LA :ASVspoof2019基于VCTK(Voice Cloning Toolkit)数据集,包含107名说话人,并且降采样到16kHz,16bits,按说话人划分为3个子集(即train、dev、eval)。ASVspoof2019使用了19种TTS/VC算法(A01-A19),其中A01-A06,作为已知数据用于训练集(train)和验证集(dev),其余作为未知数据用于测试集(eval),具体如下图所示。 ASVspoof2021不提供训练集和验证集,仅提供测试集,则由13种TTS/VC算法(A07-A19 in ASVspoof2019 )生成,并引入了7种不同的codec模拟电话传输。
PA :在 LA 的基础上通过卷积信道脉冲响应的方法加入了信道因素,还有重放样本。
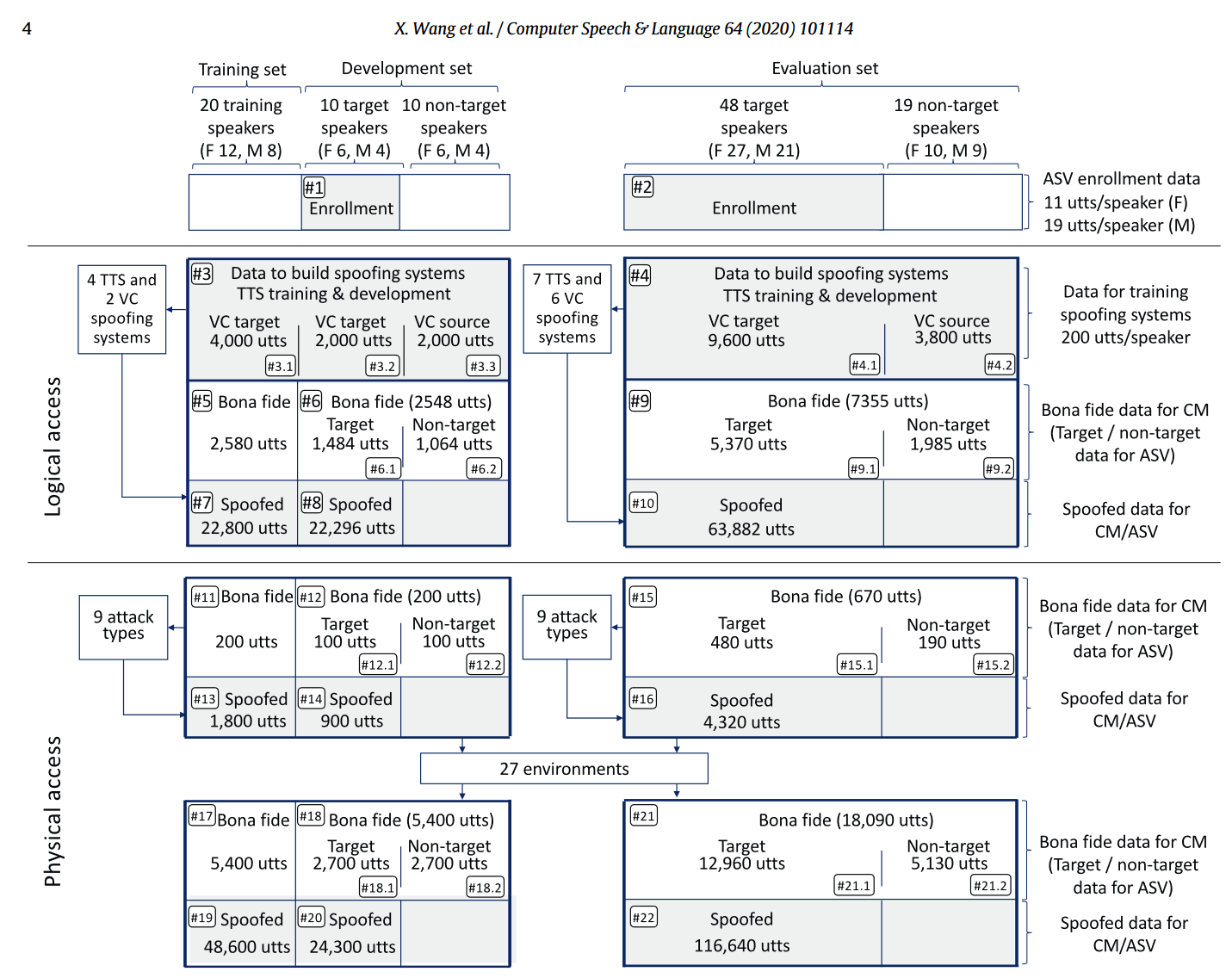
DF:DF组的数据集是ASVspoof2021全新引入的,主要来自于ASVspoof2019 LA数据集和其他的数据集,音频总共由超过100种不同的算法生成。所有数据被分为bonafide和spoofed两类。所有的数据都经过了有损的编码-解码操作引入了相应的失真,codec配置如下。为了促进应对多种或未知的伪造手段,比赛提交前不提供具体的压缩和解压缩信息以及其他的元信息(如比特率)。
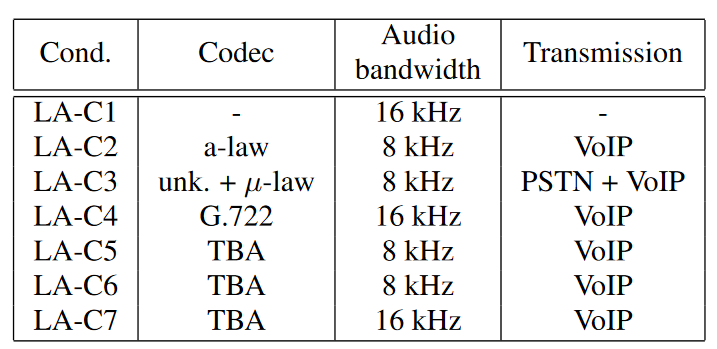
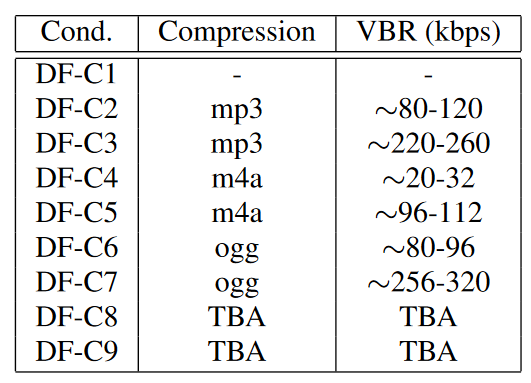
CM Baseline
ASVspoof2019中使用CQCC-GMM,LFCC-GMM作为Baseline,后端同为512-GMM模型,前端有所区别。
ASVspoof2021中又加入了LFCC-LCNN-LSTM和RawNet2两个基于神经网络后端的Baseline,这两个模型同时也是ASVspoof2019中LA single model表现最好的,之后有时间会补充展开介绍。
Metric
EER
EER时FAR=FRR时的错误率,表征一个ASV系统或CM系统的性能。通过调节ASV系统的threshold,使得FAR=FRR。在DF组,采用EER作为最终指标。
t-DCF:比赛采用的主要指标
加入CM系统后,系统有两个两个不同的目标,即说话人识别正确和排除spoof样本,存在两个threshold, $\tau_{asv}$ $\tau_{cm}$,如何评价系统的综合性能成为了一个新的问题。t-DCF在DCF的基础上,综合考虑了在评估集成了CM的ASV时的需求,将CM性能和ASV性能综合考量,表达式如下: $$ min t-DCF=\min_{\tau_{cm}}{\frac{C_0+C_1P^{cm}{miss}(\tau{cm})+C_2P^{cm}{fa}(\tau{cm})}{t-DCF_{default}}} $$
$P_{miss}$ 和$P_{fa}$是CM系统在threshold $\tau_{cm}$下的miss rate和false alam rate
$C_i$是由ASV系统的决定的系数
Reslts and Main Method
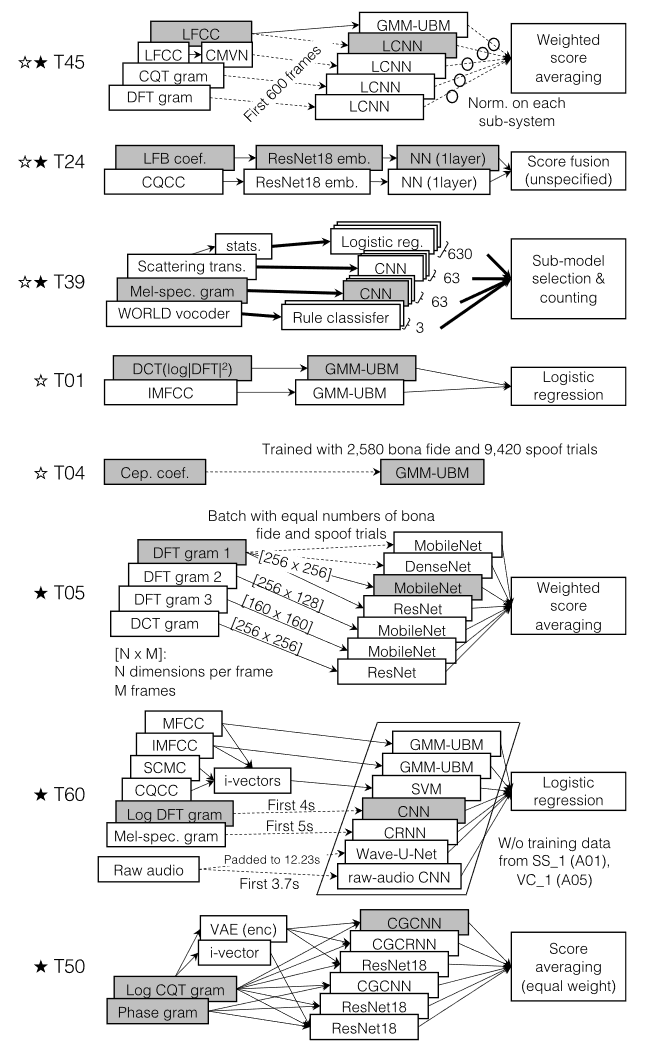
Single Model
ASVspoof2019LA挑战中表现最好的单个模型为LFCC-LCNN,LFB-ResNet18-NN, Mel-CNN,STFT-GMM,Ceps-GMM。
Model Fusion(模型融合)
参考:https://blog.csdn.net/weixin_41891249/article/details/82117228
Model fusion就是训练多个模型,然后按照一定的方法集成过个模型,应为它容易理解、实现也简单,同时效果也很好,在工业界的很多应用,在比赛中也经常拿来做模型集成。可以通过数学证明模型,随着集成中个体分类器数目T 的增大,集成的错误率将指数级下降,最终趋向于零。具体证明在周志华和李航老师的书中都有。ASVspoof所有的提交最后也基本都使用了Model Fusion来提高最后的成绩。Fusion的方法主要有Score Averaging和Voting。
##