 Channing Chen's Blog
Channing Chen's Blog

随着科学技术的迅猛发展,人们参与生产生活的各种工具变得越来越先进。然而,从安全的角度来讲,技术越高级越复杂,就会存在越多的安全漏洞。万物互联,可能也意味着每一个不起眼的设备的不起眼的细节背后都存在可以被黑客利用的漏洞。攻击面大了,信息安全工作任重道远。
个人简介
我是陈钱牛,现在是浙江大学 NGICS 项目计算机方向的硕士研究生,同时我也是浙江大学网络安全中心的一员,跟随卢立老师学习数据安全、物联网安全相关的知识,从事相关的科研工作。我本科毕业于西安交通大学电气工程及其自动化专业,一直以来对工控系统、工业互联网具有浓厚的兴趣。
我的朋友们都知道我是一个在生活上马虎,但是在学习、工作上非常热情、专注和投入的人。尽管我住在工程师学院,在没课的时候,我都会早早起床,赶早班车通往玉泉校区的校车,然后在实验室里泡一天。我每周至少有四天都是和我们方向的其他三名同学一起在实验室里看论文,写代码,做实验。我很重视与老师、同学之间交流的机会。我们每周会举行一次小组会和一次大组会,大平台还有一次月度的学术交流,每一次交流会上我都会好好准备,认真听取他人的报告和建议,同时也积极地提出问题,热情地参加到讨论中去。
从开学以来,我一直在从事对抗性样本攻击对声纹识别系统的危害和防御的相关研究工作,具体来说,可以分为攻击和防御两大块,但是目前工作重心在前半部分。
相关工作
声纹识别系统
随着物联网的普及,智能家居中大量应用了智能语音系统,声纹识别系统也得到了大规模的发展和应用。总的来说,声纹识别系统也存在其局限性,但是相较于其他生物认证技术具有以下四点突出的优势:
- 使用方便:非接触,和智能语音设备配合工作
- 硬件成本低:除了智能设备已有的麦克风无需额外的设备
- 可实现持续认证 :防止利用一次认证的漏洞进行攻击,提高可靠性
- 应用场景广:支持远程认证、刑侦破案、军事监听等
声纹识别系统一般来说可以分为认证系统和识别系统。认证系统是面向单用户的,能够给出接受和拒绝两种结果;识别系统在给出接受和拒绝结果的同时还需要做到识别用户是谁。从技术实现上来说,识别技术是做多次认证过程,然后取一个可信度最高的解。
声纹识别的另一个重要的分类是根据文本相关性来分类,所谓文本相关就是说只能对特定内容的一段话进行认证,比如 “OK,google” 等。一般认为文本相关的声纹识别相较于文本无关可以做到更好的鲁棒性。目前文本相关系统和文本无关系统都得到了广泛的应用,其实现的过程也有很多重叠的地方。目前声纹识别系统的主要模型有GMM-UBM、i-vector、x-vector以及面向未来的神经网络的end-to-end。

对抗性样本攻击
尽管深度学习模型能够在某些领域达到甚至超过人类水平,比如人脸识别,物体识别,手写文字识别等等。但是,在很多工作中,神经网络相对于高维的输入还是表现得过于线性化,容易出现判断结果依赖于训练集中出现过的情况,从而无法对训练集之外的异常做出合理的判断。对抗性样本攻击就是针对于机器学习模型的不足而提出的一种攻击手段。攻击者只需要在样本上加入一些针对性的轻微的噪声,就能通过和线性模型的参数进行点乘累计造成很明显的变化,从而让机器判断发生巨大的偏差,以高置信度判断为错误的结果。
如下图是图像领域中,在 ImageNet 上的典型的对抗性攻击案例(ICLR 2015)。图中熊猫图片在加入人眼无法察觉的噪声之后就会被机器以高置信度识别为长臂猿。

图像领域中,在 ImageNet 上的对抗性攻击案例(ICLR 2015)
不难看出,对抗性样本攻击的实现过程最终就是得到了一个对抗性扰动,以下就是对抗性样本攻击生成的基本实现原理。第一行公式实现的是有目标攻击,即攻击目的是让识别结果为攻击者预期的方向。第二行公式实现的是无目标攻击,即攻击目的是让识别结果发生错误即可,至于最终结果没有具体的要求。
$$
\begin{align}
&min& L(x_{input}+\delta,y_{target})+\alpha\cdot |\delta|_2 \
&or \ min &-L(x_{input}+\delta,y_{target})+\alpha\cdot |\delta|_2 \
&&|\delta|_2<\epsilon
\end{align}
$$
$L(x_{input},y_{label})$:目标函数
$x_{input}$:输入音频
$y_{origin}$:音频原来对应的说话人的标签
$y_{target}$:攻击预期的结果
$\delta$:叠加的对抗性噪声,最终要求的变量
$\epsilon$:$L_2$ 范数噪声限幅,防止人耳感知攻击
对抗性样本不仅在白盒攻击上卓有成效,而且天生具备迁移性。研究人员发现,对抗样本可以在不同的参数、机器学习模型的训练数据集之间进行,甚至可以跨不同的机器学习技术进行。这使得对抗性样本攻击具有真实的威胁。当攻击者想要攻击他不知道内部实现细节的受害模型的时候,他可以先训练一个替代的模型,然后为替代的模型训练对抗性样本,再用这个对抗性样本去攻击原来的模型。
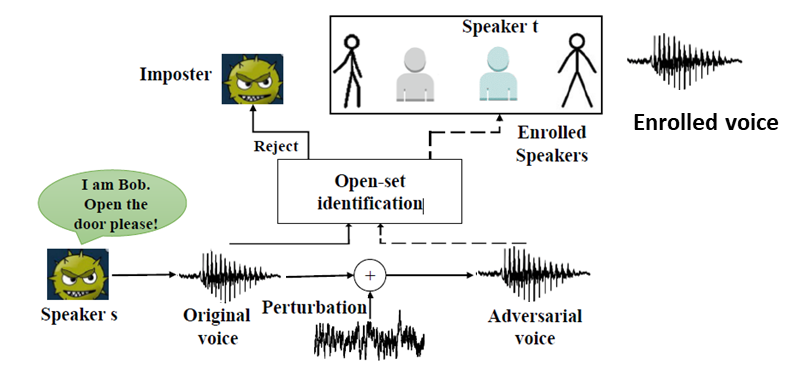
声纹认证系统中的的对抗性攻击案例”FakeBob”(IEEE S&P, 2021)
目前在声纹识别系统领域已经有不少对抗性样本攻击的案例,但是大多都是在针对某段音频产生了对抗性样本,再使用扬声器来播放这段音频样本来进行攻击,甚至是不通过空气进行攻击。这并不能真正地对声纹识别系统产生足够的威胁,因为在现实中这样的攻击方式太明显,条件太苛刻,不具有可操作性。目前在图像领域中已经有了不少物理攻击的案例,比如让人穿上一件印有特殊花纹的衣服让目标检测的系统无法识别出来等。我们也希望能够探索出在物理空间中对智能语音系统进行实际可操作的黑盒攻击方法,以产生切实有效的威胁,从而推动防御方法的发展。
目前这方面的工作仍在持续推进中。
防御方法研究
对抗性样本攻击是机器学习尤其是神经网络的天敌,尽管目前已有很多种防御方法,但是针对对抗性样本攻击的防御在总体上显得很被动,而且实现代价大,难以做到全部覆盖。具体来说,现有的防御方法往往是针对于已有的对抗性攻击手段提出的,然而新的对抗性攻击方法在不断的被提出。总的来说针对对抗性样本攻击的防御方法主要存在于以下三个方向上。
- 在学习过程中修改训练过程或者修改的输入样本。
- 修改网络,比如:添加更多层/子网络、改变损失/激活函数等。
- 当分类未见过的样本时,用外部模型作为附加网络。
声音领域的对抗性样本攻击同样难以防御,但是声音领域的对抗性样本攻击,或者说大部分的面向智能语音设备的攻击手段具有一个共同点,那就是它们都是通过扬声器来攻击的。因此,我们计划后续开展一项辅助声纹识别系统和语音识别系统的活体检测方法的研究,即直接识别发声源是不是人,如果不是就直接拒绝授权,从根源上防御攻击。具体工作还在预研准备阶段,因此就不在此深入探讨了。
总结
以上就是我这两个月不到的时间以来的主要学习和工作情况。我认为我的工作在工业控制系统安全中也具有一定的应用潜力。一是工控系统中也会用到声纹识别技术来做认证;二是工控安全中也会有各类具有一定时间规律的声波或者是数据采样点,比如大机器设备工作时产生的噪声能够在有效地反应机器的工作状态,接下来我们可能会在声纹识别的基础上来做工业设备的故障检测,在人能察觉到故障前识别出发出警报。就像王文海老师在月报交流会上所说,大平台的不同方向之间需要不断去交流探讨交叉融合的结合点。只有我们从各自擅长的领域出发,才能发挥出各自最大的优势。
我的研究生生活非常充实,尽管只有不到两个月时间,但是我觉得我学到了很多知识和技术,同时也结交了很多良师益友。在未来,我一定会继续努力,全面提高自身的素质和能力,发扬工匠精神,时刻准备着奉献我的才智,只为为国铸盾!
参考文献
[1] Goodfellow I J, Shlens J, Szegedy C. Explaining and harnessing adversarial examples[J]. arXiv preprint arXiv:1412.6572, 2014.
[2] Chen G, Chen S, Fan L, et al. Who is real bob? adversarial attacks on speaker recognition systems[J]. arXiv preprint arXiv:1911.01840, 2019.
[3] Yuan X, He P, Zhu Q, et al. Adversarial examples: Attacks and defenses for deep learning[J]. IEEE transactions on neural networks and learning systems, 2019, 30(9): 2805-2824.
[4] Szegedy C, Zaremba W, Sutskever I, et al. Intriguing properties of neural networks[J]. arXiv preprint arXiv:1312.6199, 2013.
[5] Alexey Kurakin, et al. Adversarial examples in the physical world. arXivpreprint arXiv:1607.02533, 2016.
[6] Xu K, Zhang G, Liu S, et al. Evading real-time person detectors by adversarial t-shirt[J]. arXiv preprint arXiv:1910.11099, 2019, 3.