Channing Chen's Blog
Channing Chen's Blog
NVC-Net: Voice conversion的SOTA工作
Paper: NVC-Net: End-to-End Adversarial Voice Conversion
这篇是Sony团队提出的语音转换领域的SOTA工作,亮点在于
- non-parallel
- zero-shot
- fast inference (3600kHz on NVIDIA V100)
传统VC的痛点
【平行训练集】传统的VC采用平行训练集进行训练,即训练集源语音和目标语音的文本内容是一致的。这种方式一方面存在对齐问题,需要预处理,另一方面数据采集是非常耗时且低效的。这些通点使得基于GAN的非平行训练方式得到了快速的发展。现在非平行训练的VC效果已经可以和平行方式的VC相媲美。
【输入音频建模】音频信号时域分辨率高(例如16kHz),信息量庞大,难以直接输入处理。因此常见的解决方法是通过提取语音特征降低输入维度,后续再通过声码器(vocoder)从特征还原语音。然而,传统的声码器(WORLD, STRAIGHT等)经常引入人造痕迹(如类金属噪声等)。为了解决这个问题,现在有很多复杂的神经网络声码器(autoregressive和non-autoregressive)。 其中autoregressive vocoder(e.g. WaveNet,WaveRNN)推理慢,难以运用到real-world的场景下(实时)。尽管non-autoregressive vocoder(e.g. WaveGlow)能够快速推理, 内存需求和计算量很大。尽管lightweight vocoder(e.g., MelGAN, Parallel WaveGAN)解决了内存问题,但是存在特征匹配的问题,并且生成的语音可能会产生噪声或碰撞。
【zero-shot】传统的语音转换研究对于unseen voice conversion 的关注较少。AutoVC通过预训练说话人编码器和bottleneck层,对语音信息、说话人信息进行接纠缠,实现了zero-shot voice conversion。然而,说话人编码器不能泛化到unseen speaker上,因为说话人的embedding是分散的。
Main Contribution
- NVC-Net: many-to-many, non-parallel, disentanglement, raw audio input.
- 无需额外训练vocoder,不存在特征不匹配问题,快速推理
- zero-shot
相关工作
VAE-based:通过调整decoder来限定输出语音的身份信息,poor-quality
GAN-based:不需要假定数据分布,能够自动学习捕获真实语音的分布,生成听感自然的语音。最早的研究工作基于CycleGAN。学习源说话人到目标说话人的语音特征的mapping,结合adversarial loss, cycle-consistency loss, identity mapping loss。后来的StarGAN-VC显示出了出色的语音转换性能。还有人证明了GAN能够提高VAE-based模型,但是在音频领域的应用比图像领域更加充满挑战性,因为语音是高度周期性的,并且人耳对不连续是非常敏感的,输出的语音需要高时域分辨率。
解纠缠:将语音看成是说话人身份和语音内容两部分的组合,通过解纠缠技术、语音识别技术将其分离。通过语音识别模型提取语音相关的特征,再通过与说话人相关的模型将这些特征转换成目标说话人的特征。
文章强调其他工作大部分都是在语音的中间表征(语音特征或频谱等)上进行的,甚至有的需要用到监督学习的鲁棒的vocoder,少有直接在原始音频上进行转换的。
VNC-Net
Training Objectives
Adversarial loss $\mathcal{L}_{adv}(E_c,E_s,G)$
Reconstruction loss $\mathcal{L}_{rec}(E_c,E_s,G)$
Content preservation loss $\mathcal{L}_{con}(E_c,G)$
Kullback-Leibler loss $\mathcal{L}_{kl}(E_s)$
Final loss $\mathcal{L}(E_c,E_s,G)$
Components
inherited from MelGAN and WaveNet
Content encoder. 全卷积网络,能够接收任何长度的信号。它将raw audio$(1\times T)$映射到content representation $(d_{con},T/256)$。包含四个降采样块,每个块包含4个residual blocks和1个 strided convolution。最后是两个GELU激活的卷积层。
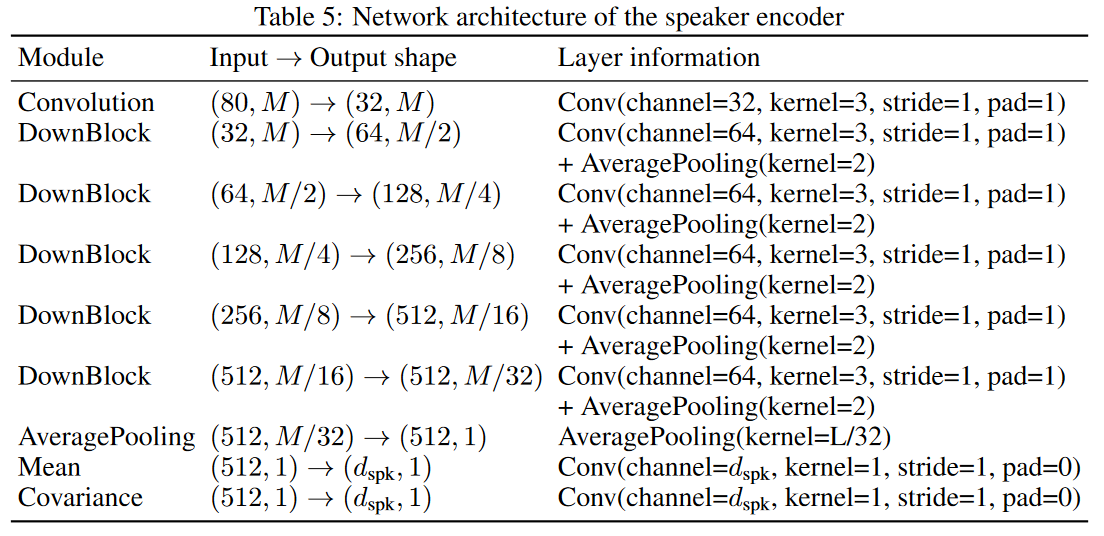
Speaker encoder.
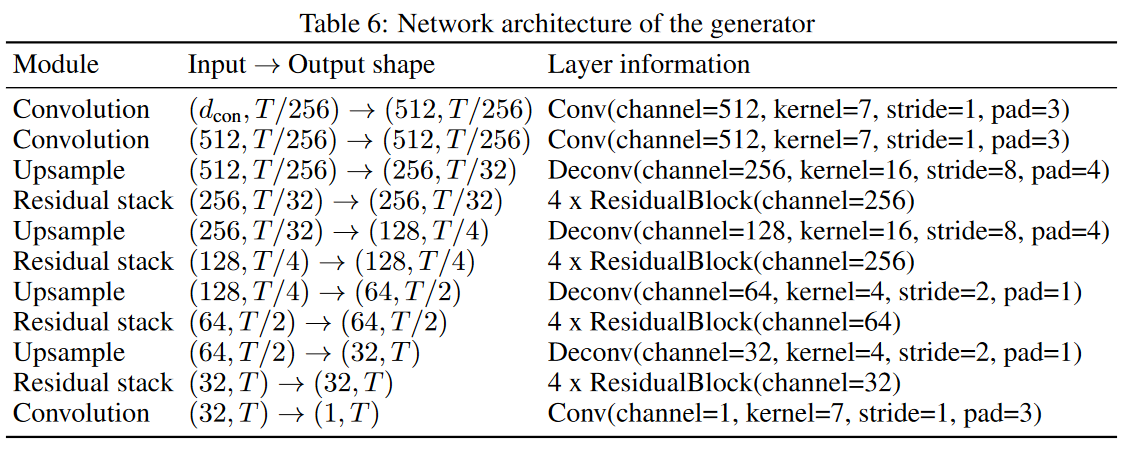
Generator. 继承自MelGAN,输入从语音特征转换成content representation。相当于是Content encoder的镜像,但是在Residual stack中输入speaker embedding。speaker embedding首先经过$1\times1$的卷积降低维度成和content representation的feature map一样。

数据增强
众所周知在训练GAN时若数据不足会导致过拟合,为了让模型能学到语义信息而不是“记住”输入信号,采用了一些数据增强措施。
将信号相位改变180度对人类听觉感知是没影响的,因此可以采取输入乘上-1的方式;
还有就是对输入进行随机幅度缩放(0.25~1);
为了降低伪影,在计算重建loss时在真实波形中引入少量时间抖动。
这些措施都不会改变speaker identity或content information。
此外,对于speaker encoder来说,还采取了音频切小段再随机重组的方式,从而更好地避免内容信息泄漏到speaker embedding里,利于解耦。
实验
数据集:VCTK,44小时,109说话人,English。
采样率:22050Hz
train-test:9-1
优化器:Adam
batchsize:8(输入是32768个采样点~1.5s)
GPU:4 * NVIDIA V100
训练时间:约15min/epoch
Baseline:
- StarGAN-VC2:https://github.com/SamuelBroughton/StarGAN-Voice-Conversion-2
- Blow:https://github.com/joansj/blow
- AutoVC:https://github.com/auspicious3000/autovc
Traditional voice conversion
Zero-shot voice conversion
Disentanglement analysis
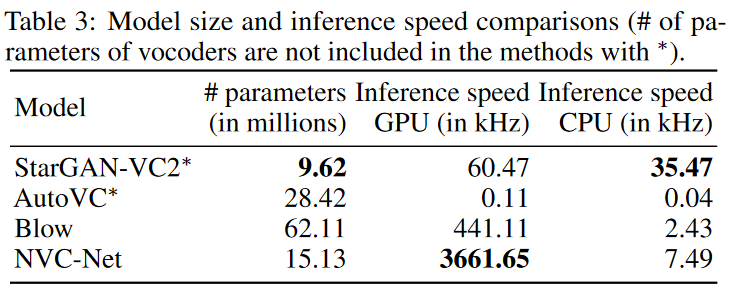
Inference speed and model size.
Inference的速度非常快
Latent embedding visualization
Model details